
ScyllaDB: How To Analyse Cluster Capacity?

I had the privilege to give a talk at ScyllaDB Summit 2024, where I briefly addressed the problem of analysing remaining capacity in clusters. It requires a good understanding of ScyllaDB internals to plan your computation cost increase when your product grows or to reduce cost if the cluster turns out to be heavily over-provisioned. In my experience, clusters can be reduced by 2-5x without latency degradation after such an analysis. In this post, I explain how to analyse CPU and disk resources properly with more details.
How Does ScyllaDB Use CPU?
ScyllaDB is a distributed database, and one cluster typically contains multiple nodes. Each node can contain multiple shards, and each shard is assigned to a single core. The database is built by the Seastar framework and uses a shared-nothing approach. All data is usually replicated in several copies, depending on a replication factor, and each copy is assigned to a specific shard. As a result, every shard can be analysed as an independent unit and it efficiently utilises all available CPU resources without any overhead from contention or context switching.
Each shard has different tasks, which we can divide into two categories: client request processing or maintenance tasks. All tasks are executed by a scheduler in one thread pinned to a core, giving each one its own CPU budget limit. Such clear task separation allows isolation and prioritisation of latency-critical tasks of request processing over less important ones. As a result of such design, the cluster handles load spikes more efficiently and provides gradual latency degradation under heavy load. You can find more details about this architecture at this link.
Another interesting result of this design is that ScyllaDB supports workload prioritisation. In my experience, this approach ensures that critical latency is not impacted during less critical load spikes. I can’t recall any similar feature in other databases. Such problems are usually tackled by having 2 clusters for different workloads. But keep in mind that this feature is available only in the enterprise licence.
However, background tasks may occupy all remaining resources, and overall CPU utilisation in the cluster appears spiky. So, that’s not obvious how to find real cluster capacity.
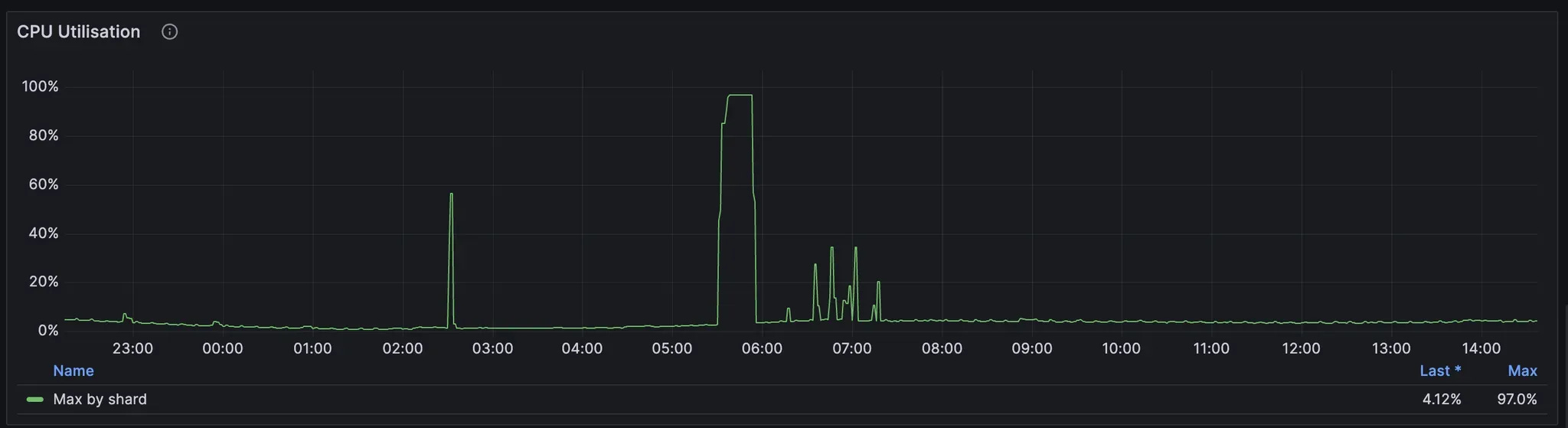
It’s easy to see 100% CPU usage with no performance impact. If we increase the critical load, it will consume the resources (CPU, I/O) from background tasks. Background tasks’ duration can increase slightly, but it’s totally manageable.
The Best CPU Utilisation Metric
How can we understand the remaining cluster capacity when CPU usage spikes up to 100% throughout the day, yet the system remains stable?
We need to exclude maintenance tasks and remove all these spikes from the consideration. Since ScyllaDB distributes all their data by shards and every shard has its own core, we take into account max CPU utilisation by a shard excluding maintenance tasks (you can find other task types here). I usually exclude only compaction and streaming, as they contribute the most to such spikes.
In my experience, we can keep the utilisation up to 60-70% without visible degradation in tail latency.
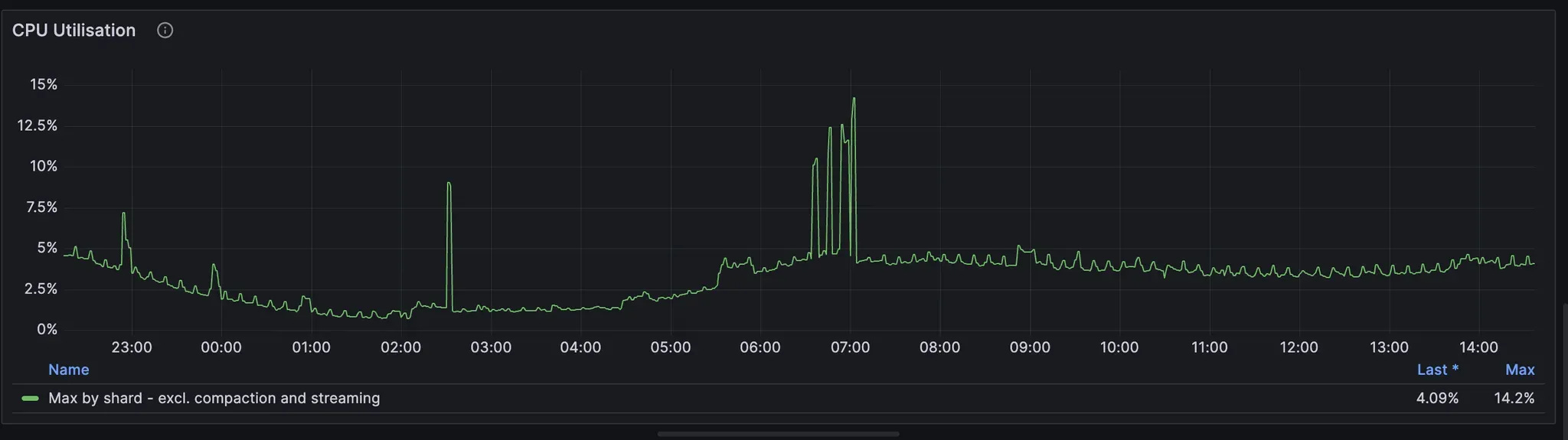
Example of a Prometheus query:
max(sum(rate(scylla_scheduler_runtime_ms{group!="compaction|streaming"})) by (instance, shard))/10
You can find more details about the ScyllaDB monitoring stack by this link. In this article, used PromQL queries to demonstrate how to analyse key metrics effectively.
However, I don’t recommend rapidly downscaling the cluster to the desired size just after looking at max CPU utilisation excluding the maintenance tasks.
First, you need to look at average CPU utilisation excluding maintenance tasks across all shards. In an ideal world, it should be close to max value. In case of significant skew it definitely makes sense to find the root cause. It can be an inefficient schema with an incorrect partition key or an incorrect token-aware/rack-aware configuration in the driver.
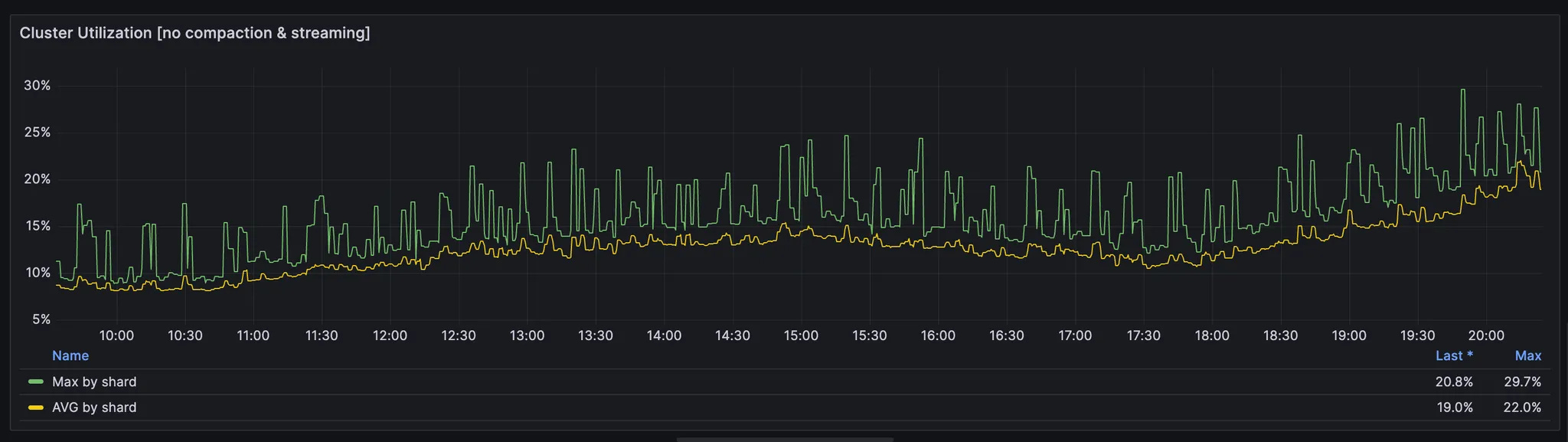
Second, you need to take a look at average CPU utilisation of excluded tasks for some your workload specific thing. It’s rarely more than 5-10% but you might need to have more buffer if it uses more CPU. Otherwise compaction will be too tight in resources and read start more expensive in respect to CPU and disk.
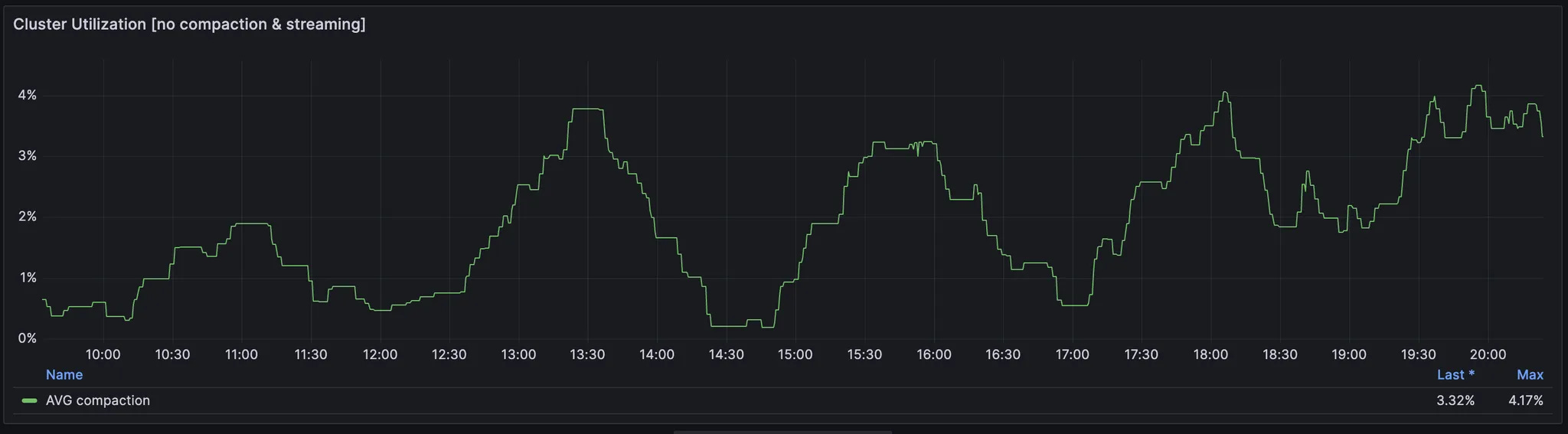
Third, it’s important to downscale your cluster gradually. ScyllaDB has in memory row cache which is crucial for ScyllaDB. It allocates all remaining memory for the cache and with the memory reduction hit rate might drop more than you expected. Hence, CPU utilisation can be increased unilinearly and low cache hit rate can harm your tail latency.
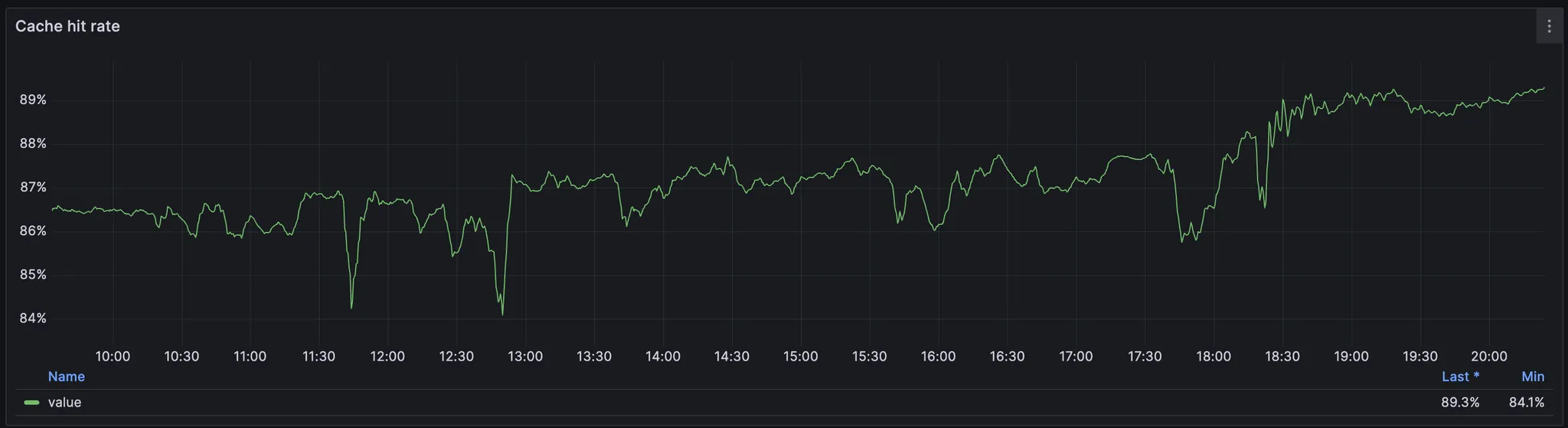
1 - (sum(rate(scylla_cache_reads_with_misses{})) / sum(rate(scylla_cache_reads{})))
I haven’t mentioned RAM in this article as there are not many actionable points. However, since memory cache is crucial for efficient reading in ScyllaDB, I recommend always using memory-optimised virtual machines. The more memory, the better.
Disk Resources
ScyllaDB is a LSMT-based database. It means that it is optimised for writing by the design and any mutation will lead to new appending new data to the disk. The database periodically rewrites the data to ensure acceptable read performance. Disk performance plays crucial role in overall database performance. You can find more details of write path and compaction in the scylla documentation. There are 3 important disk resources we will discuss here: Throughput, IOPs and free disk space.
All these resources depend on the disk type we attached to our ScyllaDB nodes and their quantity. But how can we understand the limit of the IOPs/throughput? There 2 possible options:
Any cloud provider or manufacturer usually provides performance of their disks and you can find it on their website. For example, NVMe disks from Google Cloud.
Actual disk performance can be different compared to numbers from the manufacturers. The best option might be just to measure it. And we can easily get the result. ScyllaDB performs a benchmark during installation to a node and stores the result in the file io_properties.yaml. The database uses these limits internally for achieving optimal performance.
disks:
- mountpoint: /var/lib/scylla/data
read_iops: 2400000 //iops
read_bandwidth: 5921532416//throughput
write_iops: 1200000 //iops
write_bandwidth: 4663037952//throughput
file: io_properties.yaml
Disk Throughput

sum(rate(node_disk_read_bytes_total{})) / (read_bandwidth * nodeNumber)
sum(rate(node_disk_written_bytes_total{})) / (write_bandwidth * nodeNumber)
In my experience, I haven’t seen any harm with utilisation up to 80-90%.
Disk IOPs
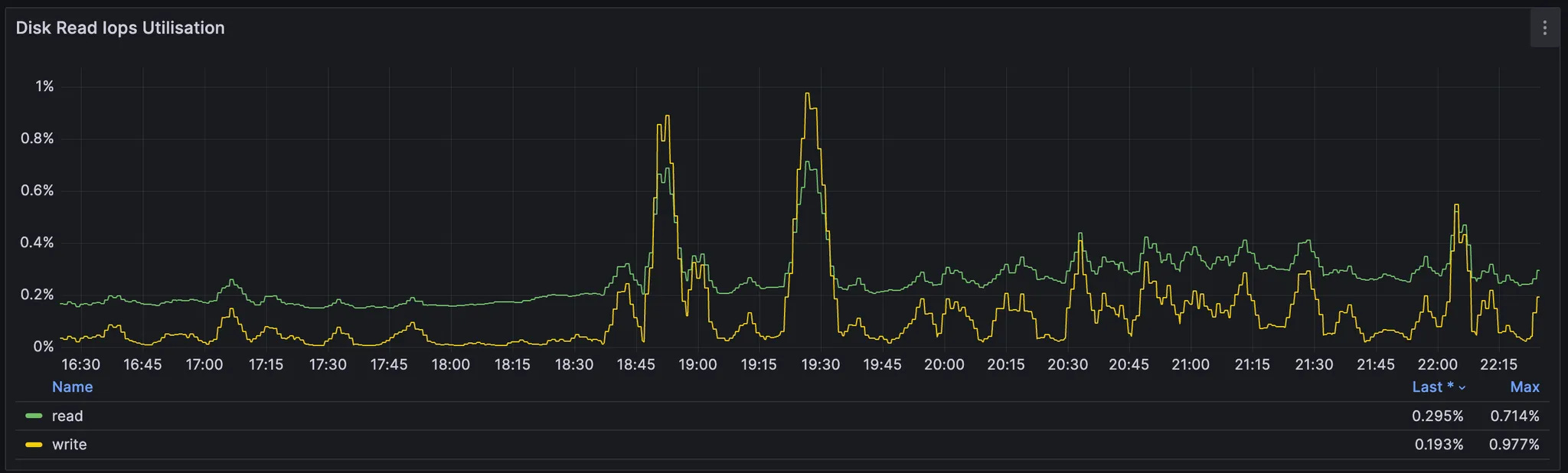
sum(rate(node_disk_reads_completed_total{})) / (read_iops * nodeNumber)
sum(rate(node_disk_writes_completed_total{})) / (write_iops * nodeNumber)
Disk free space
It’s crucial to have significant buffer in every node. In case running out of space the node will be basically unavailable and it will be hard to return it back. However, additional space requires for many operations:
Every update, write, or delete will be written to the disk and allocate new space.
Compaction requires some buffer during cleaning the space.
Back up procedure.
The best way to control disk usage is to use Time To Live in the tables if it matches your use case. In this case irrelevant data will expire and clean during compaction.
I usually try to keep at least 50-60% of free space
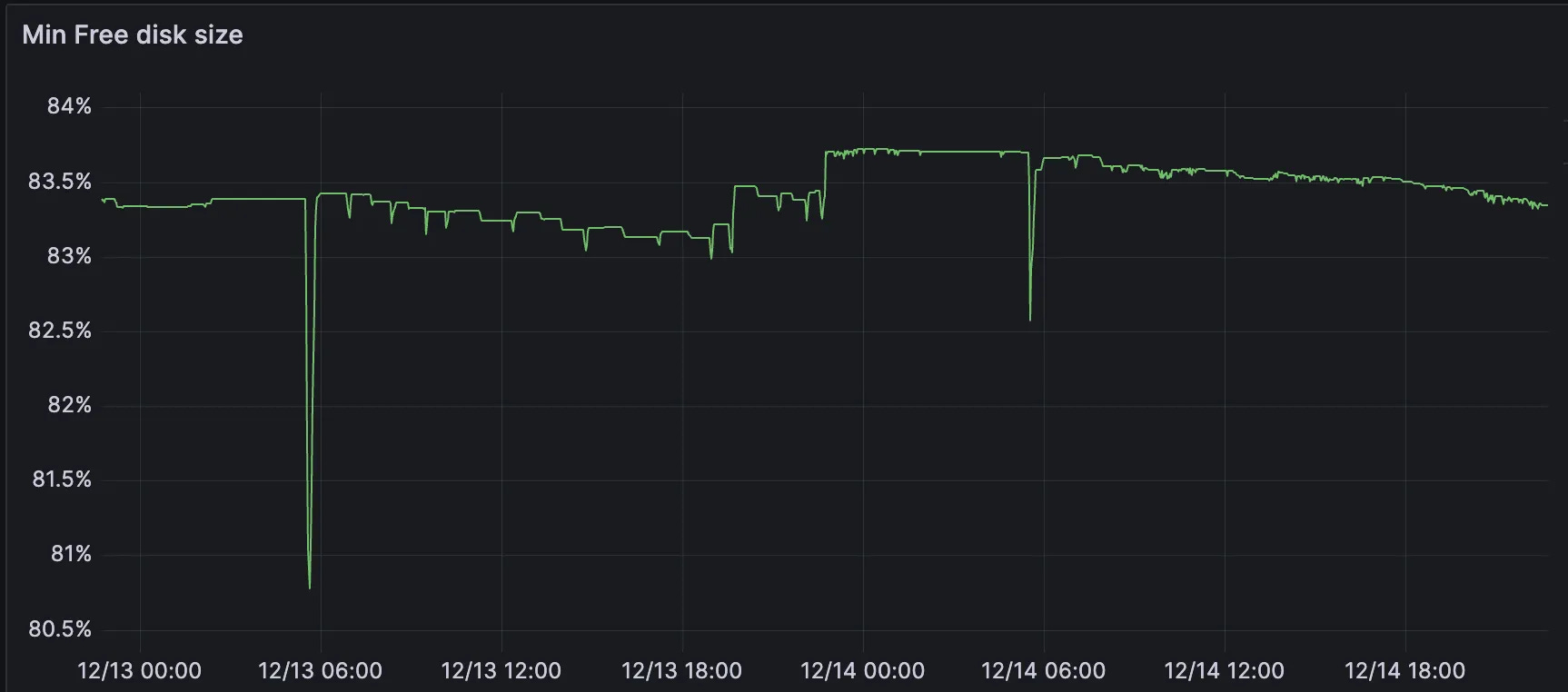
min(sum(node_filesystem_avail_bytes{mountpoint="/var/lib/scylla"}) by (instance)/sum(node_filesystem_size_bytes{mountpoint="/var/lib/scylla"}) by (instance))
Tablets
Most of the app has significant change in load during day or week. ScyllaDB is not elastic and you need to have provisioned cluster for the peak load. So, you waste a lot of resources during a night or weekends. But that can be changed soon.
A ScyllaDB cluster distributes data across its nodes and the least unit of the data is a partition uniquely identified by a partition key. Partitioner hash function computes token to understand in which nodes data are stored. Every node has own token range, all nodes makes a ring. Adding a new node didn’t use to be a fast procedure as it required copying (it is called streaming) data to a new node, adjusting token range for neighbours, etc. In addition, it’s a manual procedure.
However, ScyllaDB introduced tablets in 6.0 version, and it provides new opportunities. A Tablet is a range of tokens in a table and it includes partitions which can be replicated independently. It makes overall process much smoother and it increases elasticity significantly. Adding new nodes takes minutes and a new node starts processing requests even before full data synchronisation. It looks like a significant step toward full elasticity which can drastically reduce server cost for ScyllaDB even more. More information about tablets you can read here. I am looking forward to test it closely soon.
Conclusion
Tablets look like a solid foundation for future pure elasticity, but for now, we need to plan clusters for peak load. To effectively analyze ScyllaDB cluster capacity, focus on these key recommendations:
Target max CPU utilisation (excluding maintenance tasks) per shard at 60–70%.
Ensure sufficient free disk space to handle compaction and backups.
Gradually downsize clusters to avoid sudden cache degradation.