
Best Practices for ScyllaDB Driver Configuration
Debugging a Re-Connection Storm with ScyllaDB and Defining Hygiene Rules for the GoCQL Driver

I love working with high-load distributed systems. Right now, my primary interest is ScyllaDB. It’s a distributed, fault-tolerant NoSQL database that is fully compatible with Apache Cassandra but provides lower latency and requires fewer resources. Some call ScyllaDB “Casandra written in C++”. I work with multiple systems based on ScyllaDB, and some of the clusters handle loads exceeding 1M RPS. In this post, I will talk about a re-connection storm that occurred in our cluster and how we debugged and mitigated it, and the driver hygiene rules we established following the incident. I also presented this story at the ScyllaDB Summit 2024, if you prefer watching, most of the information can be found there. Additionally, I have included code examples and more details in this article.
One day, we received an alert about huge latency spikes in ScyllaDB. Two nodes were overloaded. This issue repeated during peak times and usually resolved itself when traffic decreased. As an immediate workaround we disabled the binary protocol on the affected nodes but this was just a temporary mitigation.
Culprit
The problem wasn’t obvious at first glance; there were no anomalies in primary metrics. However, a clue was found in the internal CQL rate request. CQL internal inserts were thousands of times greater on the impacted nodes.
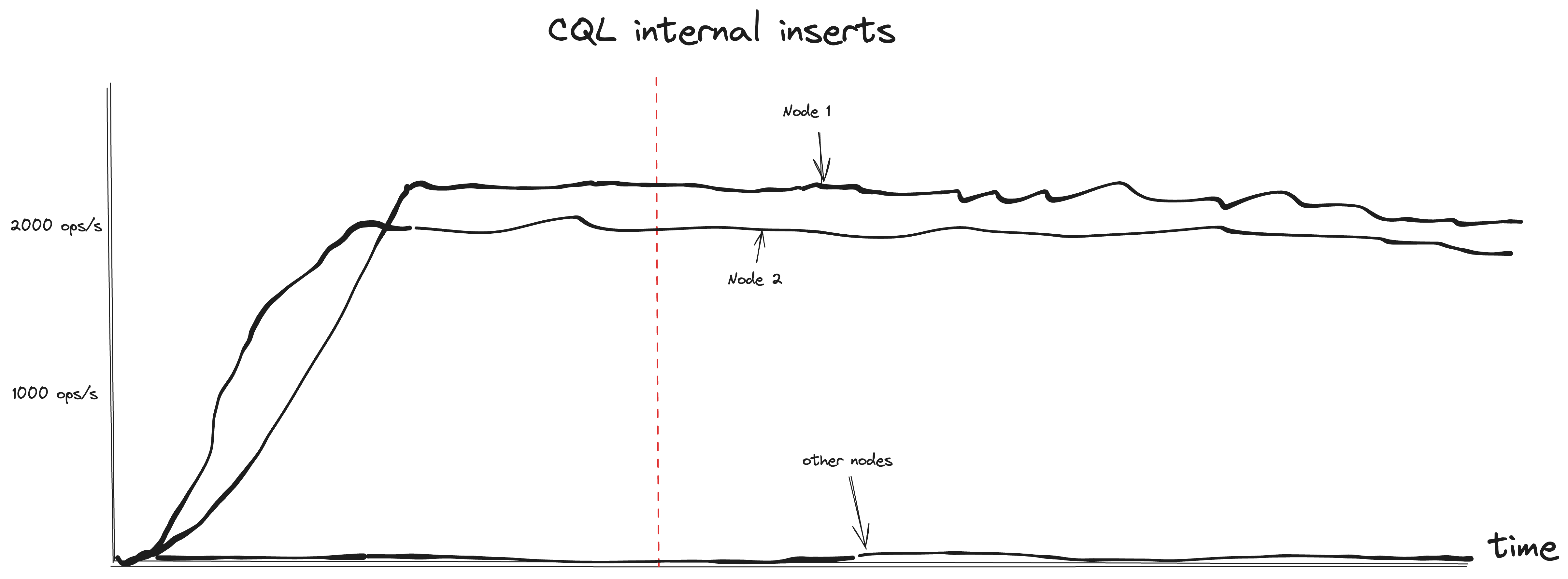
Finally, the culprit was narrowed down to the connection rate graph. There were no specific graphs in the default monitoring, so I show here a metric itself.
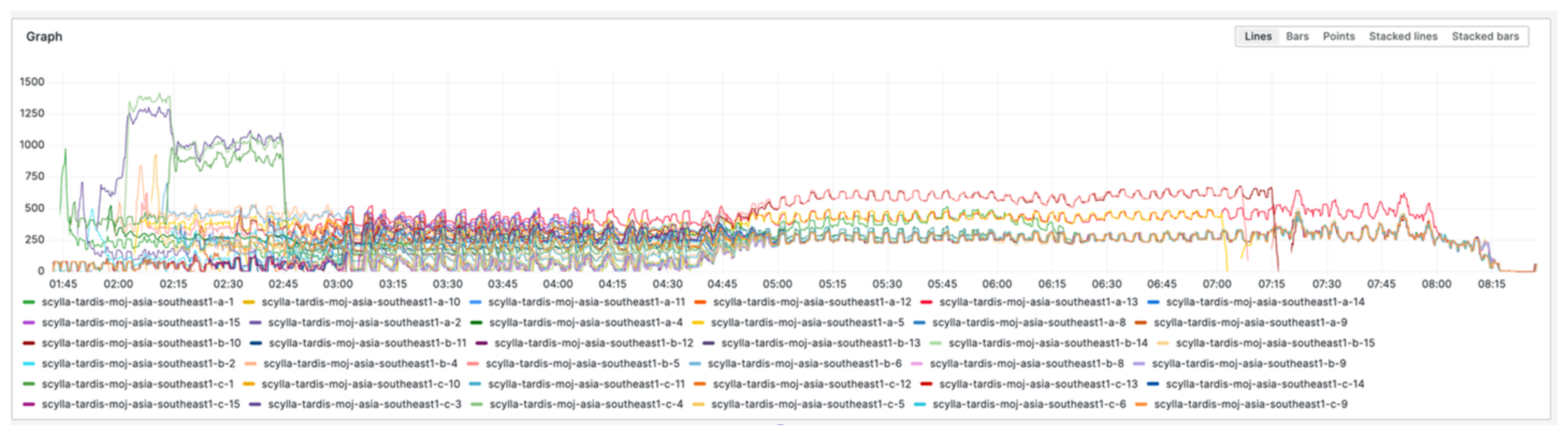
sum(rate(scylla_transport_cql_connections)) by (instance)We were experiencing a re-connection storm. Clients continually attempted to establish connections, overloading the nodes. Establishing a new connection is quite expensive as it involves writing to multiple internal tables, including the audit table, which is reflected in the CQL internal inserts.
Why did it happen?
After identifying the problem, we started looking into the ScyllaDB driver configuration. We primarily use Golang in production with default scylla gocsql driver. All settings were default except for the shard-aware configuration; we specified the shard-aware port in the host definition (host:19042). Here is our configuration (only relevant parameters. Link to sources)
func NewCluster(hosts ...string) *ClusterConfig {
cfg := &ClusterConfig{
Hosts: hosts, // ["NodeIp1:190942","NodeIp2:190942",..]
Timeout: 600 * time.Millisecond,
ConnectTimeout: 600 * time.Millisecond,
ReconnectionPolicy: &ConstantReconnectionPolicy{MaxRetries: 3, Interval: 1 * time.Second},
ReconnectInterval: 60 * time.Second,
}
return cfg
}
The driver configuration had 3 problems. Let’s explain them one by one.
Connection settings
The driver connects to a node with a 600ms timeout. On timeout error, there are 2 additional attempts with a 1-second interval. On failure, the node is marked as down. All down nodes are checked every 60 seconds (ReconnectInterval) and are marked as up on success.
What would happen if a node gets temporarily overloaded? As I mentioned above, establishing a new connection is an expensive operation, so 600ms might be insufficient. However, the client will make 2 more attempts, creating a snowball effect, and the node would never recover! Therefore, we need to increase the connect timeout and remove all retries. A 60s reconnection interval is more than enough. So we will keep it.
func NewCluster(hosts ...string) *ClusterConfig {
cfg := &ClusterConfig{
Hosts: hosts, // ["NodeIp1:190942","NodeIp2:190942",..]
Timeout: 600 * time.Millisecond,
ConnectTimeout: 12 * time.Second,
ReconnectionPolicy: &ConstantReconnectionPolicy{MaxRetries: 1, Interval: 1 * time.Second},
ReconnectInterval: 60 * time.Second,
}
return cfg
}
Timeout settings
ScyllaDB has 2 types of timeouts: client-side timeout and server-side timeout. The client-side timeout is the wait time during any query operation in the driver. The server-side timeout is the maximum time for processing requests on the server before it drops the request. You can find more explanation in the ScyllaDB documentation.
The client-side timeout in the GoCQL driver is set by Timeout parameter in ClusterConfig.
The default server-side timeout is set in the cassandra.yaml file. It can be changed for specific requests inside a query statement or in the driver’s queryBuilder.
It’s crucial to understand the difference between these timeouts and choose correct values for both. The server-side timeout should to be less than the client-side timeout. Otherwise, ScyllaDB will waste CPU resources, prevents node recovery. In our case, we had default values: 5s for the server-side timeout and 600ms for the client-side. We increased timeout to 5.2s:
func NewCluster(hosts ...string) *ClusterConfig {
cfg := &ClusterConfig{
Hosts: hosts, // ["NodeIp1:190942","NodeIp2:190942",..]
Timeout: 5200 * time.Millisecond
ConnectTimeout: 12 * time.Second,
ReconnectionPolicy: &ConstantReconnectionPolicy{MaxRetries: 1, Interval: 1 * time.Second},
ReconnectInterval: 60 * time.Second,
}
return cfg
}
Shard aware configuration
Any ScyllaDB node exposes 2 ports: a shard-aware port and a default non-shard-aware port. We used the shard-aware port in the host definition. The driver has fallback connection behavior when connecting to the shard-aware port. If the driver fails to connect to the shard-aware port, it tries to connect to the default port, which it takes from the host definition! Later, the driver terminates connection if it’s connected to the shard-aware port. This behavior appears to be designed for misconfiguration resistance, but it works incorrectly in this case.
If nodes struggle and the driver fails to connect the shard-aware port, it tries to establish the connection to same port from host definition. and even if the fallback connection is successful, it eventually closes. This creates a reconnection loop: establishing a connection to shard-aware port → timeout → fallback to shard-aware port→ disconnection/timeout.
We broke this reconnection chain by changing the port in the host definition:
func NewCluster(hosts ...string) *ClusterConfig {
cfg := &ClusterConfig{
Hosts: hosts, // ["NodeIp1:9042","NodeIp2:9042",..]
Timeout: 5200 * time.Millisecond
ConnectTimeout: 12 * time.Second,
ReconnectionPolicy: &ConstantReconnectionPolicy{MaxRetries: 1, Interval: 1 * time.Second},
ReconnectInterval: 60 * time.Second,
}
return cfg
}
Request Retry policy
Retry policy is one of the most critical settings in a distributed system. On one hand, it can significantly reduce tail latency if you use it wisely; on the other hand it increases load and can drastically reduce its ability to recover. I highly recommend not using retries by default and introducing them only after carefully considering possible consequences for the specific system. By default, the driver has a zero-retry policy (and I highly recommend keeping it). We also checked for any retry configurations in our system. Nginx, by default, has unlimited retries for gRPC upstreams! So, find last problems in our system and remove any retries there.
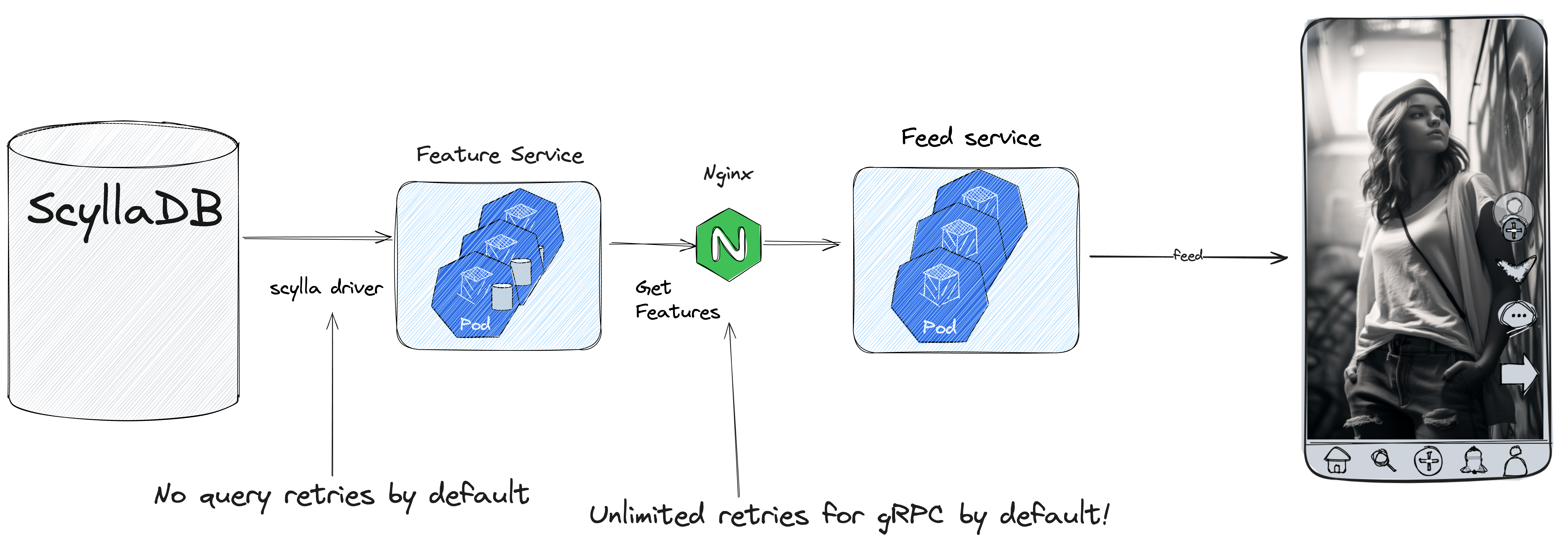
Always check all default settings in every possible source of unbounded concurrency.
Conclusion
During the debugging we defined for us several hygiene rules for GoCQL driver configuration:
Client side timeout must be greater than server side timeout.
Connection timeout must be greater than read/write timeout.
Don’t use shard-aware port in connection string.
Don’t use request/reconnection retries.
After applying these changes our ScyllaDB clusters have been very stable and we haven’t encountered any issues for a long period of time. I believe most of these rules are general and can be applied to most databases and systems. However, they are not absolute and can be adjusted to specific systems.
Resources:
Cassandra default timeout configuration: Link
Github issue about fallback connection policy: Link
GoCQL driver documentation: Link
GoCQL driver: Link
ScyllaDB timeout troubleshooting: Link
ScyllaDB shard-aware port explanation: Link
ScyllaDB nodetool commands: Link
ScyllaDB post about unbounded concurrency: Link